오늘은 크롤링 시리즈 첫번째로 BeautifulSoup을 사용해서
네이버 뉴스기사의 작성일, 제목, 주소를 크롤링해 데이터프레임으로 만드는 것까지 해보자!
1. 모듈 불러오기
import requests
from bs4 import BeautifulSoup
import timerequests: url에 접속하면 해당 url의 html 정보를 가져와준다.
BeautifulSoup: html 정보를 parsing
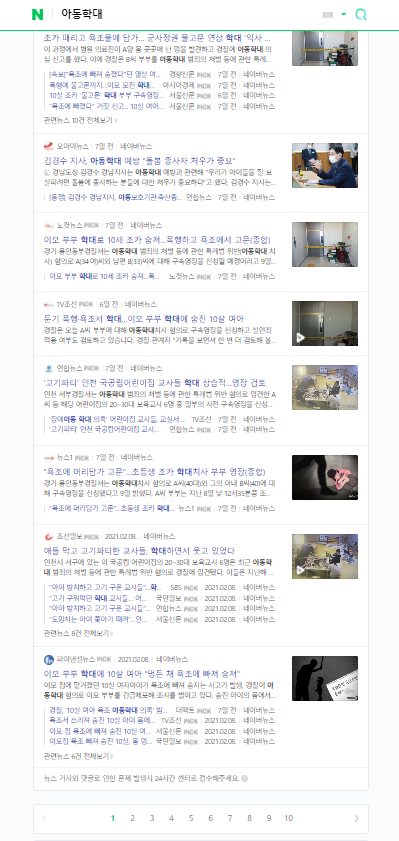
2. html 정보 가져오기
url = 'https://search.naver.com/search.naver?&where=news&query=%EC%95%84%EB%8F%99%ED%95%99%EB%8C%80&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=3&ds=2021.01.01&de=2021.01.09&docid=&nso=so:r,p:from20210101to20210109,a:all&mynews=0&cluster_rank=91&start=1&refresh_start=0'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')네이버 검색창에 "아동학대"라는 검색어를 입력한 후
뉴스 날짜 필터에서 '2021.01.01 ~ 2021.01.09' 으로 기간 설정
위의 url은 첫페이지의 url 이다.
네이버는 다음에 비해 크롤링이 잘 안되는데 이럴 경우 headers 정보를 이용하면 쉽게 html 정보를 가져올 수 있다.
3. 기사 제목 찾기
soup.find_all('a', attrs={'class':'news_tit'})
title = "찾고자하는 기사 제목" 있음을 확인
즉, value가 아닌 "속성"에 원하는 데이터 있음
[title['title'] for title in soup.find_all('a', attrs={'class':'news_tit'}) ]
한리스트에 태그 여러개이므로 반복문 사용
속성에 원하는 데이터 있으므로 ['속성명']
4. 기사 주소 찾기
[ url['href'] for url in soup.find_all('a', attrs={'class':'news_tit'}) ]주소 또한 제목과 마찬가지
5. 기사 작성일 찾기
<span class="info">2021.01.09.</span> : value에 데이터 존재 -> get_text() 함수 사용
soup.find_all('span', attrs={'class':'info'})
여기서 문제 발생!!
두번째 줄을 보면 속성명이 겹치는 탓에 쓸데없는 정보까지 딸려옴!!
차라리 날짜가 자식태그까지 자세히 가지고 있었다면 속성을 전부 써주면 되는데 오히려 날짜 태그가 더 단순함..
"날짜형식"만 가져오기위해 정규표현식 사용
dates = [ date.get_text() for date in soup.find_all('span', attrs={'class':'info'})]
import re
date_list = []
for date in dates:
if re.search(r'\d+.\d+.\d+.', date) != None:
date_list.append(date)
date_list
올바른 날짜만 가져오기 성공!
하지만 여기까지는 오로지 네이버 뉴스의 "첫페이지"만을 가져온것
사실 10개 가져올바엔 코딩이 아니라 그냥 손으로 가져오는게 더 빠르다...
첫페이지가 아닌 페이지를 넘겨서 기간내 기사 전부를 크롤링 해보자!
6. 기간 내 기사 모두 크롤링하기
여기서 중요한 것은 페이지별 url의 규칙성을 파악하는것!
첫페이지 url
두번째 페이지 url
세번째 페이지 url
페이지 넘길때마다 10씩 증가하는 규칙 발견!!
start = 1
result_df = pd.DataFrame()
while True:
try:
url = 'https://search.naver.com/search.naver?&where=news&query=%EC%95%84%EB%8F%99%ED%95%99%EB%8C%80&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=3&ds=2021.01.01&de=2021.01.09&docid=&nso=so:r,p:from20210101to20210109,a:all&mynews=0&cluster_rank=91&start={}&refresh_start=0'.format(start)
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
news_title = [title['title'] for title in soup.find_all('a', attrs={'class':'news_tit'})] # 기사 제목
news_url = [ url['href'] for url in soup.find_all('a', attrs={'class':'news_tit'}) ] # 기사 url
dates = [ date.get_text() for date in soup.find_all('span', attrs={'class':'info'})] # 기사 작성일
news_date = []
for date in dates:
if re.search(r'\d+.\d+.\d+.', date) != None: # 기사 작성일 정제
news_date.append(date)
df = pd.DataFrame({'기사작성일':news_date,'기사제목':news_title,'기사주소':news_url})
result_df = pd.concat([result_df, df], ignore_index=True)
start += 10
except: # 오류발생시 몇 페이지까지 크롤링했는지 page를 확인하기
print(start)
break데이터프레임으로 만드는게 두번째 부딪힌 난관이었다.
처음에는 데이터프레임이 아니라 리스트로 데이터를 묶었는데
그렇게 하면 리스트끼리 묶여 나중에 데이터프레임을 만들 때 문제가 생겼다.
따라서 반복문 안에서 데이터프레임을 만들고 concat 함수를 통해 합쳐 데이터 프레임을 만들었다!!

시간 관계상 끝까지 수집하지 않고 중간에 멈추었다. 예쁜 데이터프레임 완성!!
이렇게 BeautifulSoup을 활용한 크롤링 과정을 포스팅해보았다.
다음번에는 Selenium을 활용한 동적 크롤링을 포스팅 해야지!
'Data' 카테고리의 다른 글
| [python] 국민청원 크롤링 ( Selenium, BeautifulSoup ) (753) | 2021.03.28 |
|---|---|
| [python] 멜론차트 크롤링 ( Selenium, BeautifulSoup ) (741) | 2021.02.17 |
| [python] SVM, PCA kaggle 필사 (유방암 데이터) (691) | 2021.02.05 |
| [R] 데이터 시각화 with R ( 롤리팝차트 / 덤벨차트 / 슬로프차트 ) (387) | 2021.01.28 |
| [R] 데이터 시각화 with R ( 막대그래프/와플차트 ) (384) | 2021.01.26 |


