1. 가사 및 사용할 패키지 불러오기
song = readLines("기리보이 9집 가사.txt", encoding = "ANSI")
head(song) # 문장 별로 존재
library(dplyr)
library(tidytext)
library(stringr)
library(KoNLP)
library(widyr) # 동시 출현 빈도 계산하기 위한 패키지
""는 빈 줄을 의미
2. 동시 출현 빈도
동시 출현 빈도란? 그룹 단위 내에서 단어가 동시에 출현한 횟수
그룹단위는 각자 정의하기 나름
여기서는 가사 한 줄 내에서 단어가 동시에 출현한 횟수를 계산할 것
동시 출현 빈도를 계산하기 앞서 텍스트 전처리가 필요하다
1) 형태소 단위로 끊어진 데이터 생성
song = song[!(song == "")] # "" 만 존재하는 관측값 삭제
song = as_tibble(song)
song %>%
mutate(sent_order = 1:n()) %>% # 문장 순서 만들기, 중요!!
unnest_tokens(pos, value, SimplePos09) -> song_pos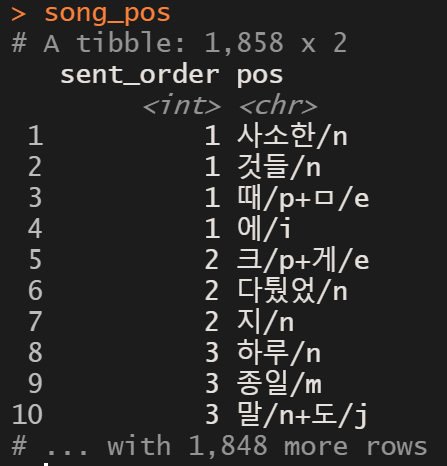
나는 "문장" 단위 내에서 단어가 몇 번 출현했는지를 계산할 것이므로
문장을 형태소 단위로 헤쳐 놓기 전에 미리 문장 단위에 번호를 생성해야 한다.
그래야 나중에 형태소만 남아 있더라도 각각의 형태소가 어떤 문장에 속해있었는지 파악이 가능하다!!
2) 불용어 전처리
#전처리된 체언 데이터 생성
song_pos %>%
filter(str_detect(pos, "/n")) %>% # 명사만 남기기
mutate(pos_clean = str_remove(pos,"/.*$")) -> n_clean
#전처리된 용언 데이터 생성
song_pos %>%
filter(str_detect(pos,"/p")) %>% # 용언만 남기기
mutate(pos_clean = str_replace_all(pos, "/.*$", "다")) -> p_clean # 용언 어미를 "다"로 대체
# 데이터 합치기
bind_rows(n_clean, p_clean) %>%
arrange(sent_order) %>%
filter(nchar(pos_clean) > 1) %>% # 글자수 1개 이상인 것만
filter(!str_detect(pos_clean, "[A-Za-z]")) -> song_result # 영어는 제외
불용어 전처리에 관한 자세한 내용은 저번 포스팅을 참고하면 된다.
저번과 달라진 점은 마지막 줄 코드인데, "형태소" 단위의 끊어내기는 한국어에 맞는 방식이다.
따라서 영어를 형태소 단위로 분석하면 의미에 맞지 않게 이상하게 분리되므로 따로 단어 단위로 분석해야한다.
나는 그냥 제거했다. (기리보이 이번 앨범 가사에는 영어가 현저히 적다 )

pos_clean 컬럼에 전처리된 형태소들이 모여있는 것을 확인할 수 있다.
3) 동시 출현 빈도 계산
song_result %>%
pairwise_count(pos_clean, sent_order, sort = T, upper = F) -> PW # upper = F는 반복출력 피해줌
# (1,2) (2,1) 중에서 하나만 출력widr 패키지의 pairwise_count() 함수를 이용하면 동시 출현 빈도를 쉽게 계산 가능하다.
아까 만든 sent_order 변수( 문장 순서) 가 여기에 쓰인다!!
count 계열의 함수를 내림차순으로 정렬하고 싶다면 sort = T를 사용하면 된다.
pairwise_count ( 텍스트 데이터, 그룹 단위 변수 )
(여기서 그룹 단위는 문장)
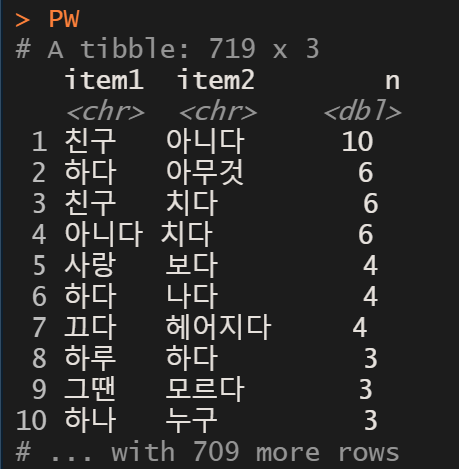
친구와 아니다가 동시에 가장 많이 출현한 단어라는 결과가 나왔다.
이는 아마도 "우리서로사랑하지는말자"라는 노래에서 후렴구가 "그냥 이대로 친구 아닌 친구"가 계속 반복돼서 나온 결과로 보인다.
4) 기준 단어로 데이터 탐색
PW %>%
filter(item1 == "사랑")filter() 함수를 사용하면 함께 자주 나오는 단어와 빈도를 확인할 수 있다.

이번 앨범은 전부 사랑과 관련된 노래이므로 "사랑"을 기준 단어로 데이터를 살펴 보았다.
사랑은 "보다" 와 같이 가장 많이 출현한 것으로 확인되었는데 이는 타이틀곡 "사랑했었나 봐"에서 "사랑"과 "봐"가 계속 같이 나타난 결과로 보인다.
사실 여기서 "봐"는 진짜로 눈으로 보다(see)의 의미가 아니지만, 가사 내용을 모르는 채 결과만 보면 오해하기 쉽다.
이런 면에서 텍스트 분석을 정교하게 하는 일은 정말 어려운 것 같다.
5) 네트워크 시각화
library(igraph)
PW %>%
graph_from_data_frame()

네트워크 시각화로 그림도 그릴 수 있다고 했지만 강의에서 자세히 다루지 않았고, 새로 공부해야할 개념들도 있어서 강의에서도 데이터 프레임을 만들어보는 선에서 끝냈다.
song_result %>%
pairwise_count(pos_clean, sent_order, sort = T, upper = F) -> PW # upper = F는 반복출력 피해줌
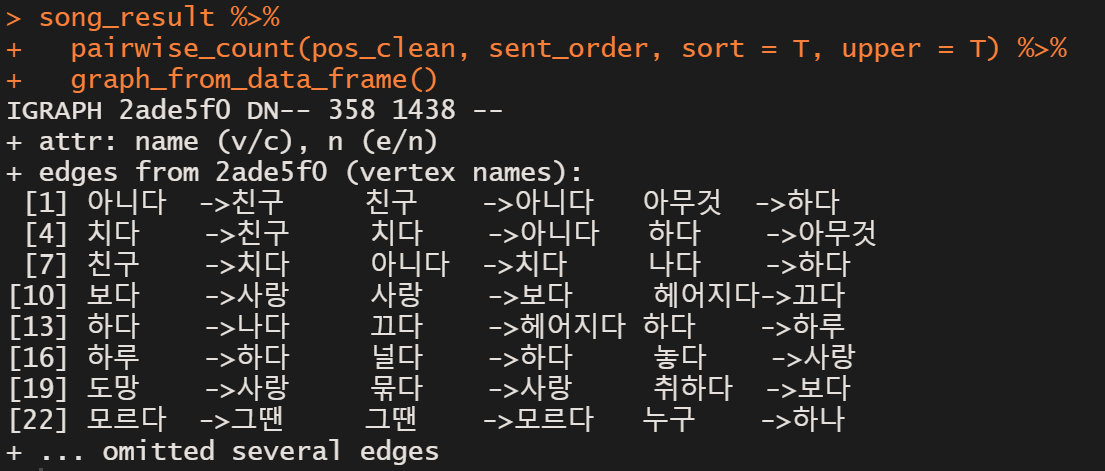
아까는 upper = F를 통해 단어가 중복되는 것을 막은채 동시 출현 빈도를 계산했는데, 이번에는 중복을 허용했다.
그럼 아니다 -> 친구, 친구 -> 아니다가 같은 숫자로 가장 많이 나오는 것을 알 수 있는데,
여기서도 아까 말한 "그냥 이대로 친구 아닌 친구"라는 후렴구 때문임을 알수 있다.
친구 -> 아니다 -> 친구 이런 구조로 인해 발생한 결과!! 알고보니 흥미롭다ㅎ
3. tf - idf
tf-idf란?
tf: 전체 문서내의 단어 빈도
idf: 단어를 가지는 문서 비율의 역수
내가 대충 이해한 tf-idf의 개념은 "해당 단위"에서 특정 단어가 얼마나 중요한가? 이다.
예를 들어 내가 1달 동안 쓴 일기를 전체 문서라고 하고 하루마다 쓴 일기 한장을 단위로 잡자.
1달 동안 쓴 일기에서 제일 많이 등장하는 단어는 아마도 "나"일 것이다. (나는 뭘 했다..뭘 먹었다...)
하지만 "나"가 단순히 일기 전체에서 많이 등장했다고 해서 "나"가 중요한 단어라고 보기는 어렵다.
내가 1월 1일에는 떡국을 먹었다는 내용의 일기를 쓰고 1월 5일에는 컴퓨터를 샀다는 내용의 일기를 썼다면,
1월 1일 일기에서 가장 중요한 단어는 "나"가 아닌 떡국이고, 1월 5일 일기에서 가장 중요한 단어는 "컴퓨터" 일 것이다.
이러한 개념을 적용하여 단어를 가지는 문서 비율의 역수를 가중치로 적용한 것이 tf-idf 이다.
여기까지는 내가 대충 이해한 개념이고, tf-idf 에 대한 자세하고 정확한 개념은 밑의 링크를 참고하면 된다.
TF-IDF (Term Frequency — Inverse Document Frequency) Algorithm
TF-IDF는 여러 개의 문서가 있을 때, 각각의 문서의 내에 있는 단어들에 수치값을 주는 방법인데, 가중치가 적용되어있다. TF-IDF를 계산하면 문서 내에 상대적으로 중요한 단어를 알 수 있다.
medium.com
song_result %>%
group_by(sent_order) %>% # 문장별로 tf-idf 계산할것이므로
count(pos_clean, sort = T) %>%
bind_tf_idf(pos_clean, sent_order, n) %>%
arrange(desc(tf_idf)) 계산은 단어의 단순 빈도를 구한 후 tidytext 패키지의 bind_tf_idf() 함수를 이용하면 쉽게 구할 수 있다.
여기서 주의할 점은 단순 빈도를 구할 때 "원하는 단위로 group_by"를 해줘야 한다는 것이다!!!
여기서는 문장 단위로 구할 것이므로 위에서 만든 sent_order 변수로 그룹핑을 해주었다.
1. 원하는 단위로 그룹핑한 후 단순빈도 계산
2. bind_tf_idf( 텍스트 단어, 그룹핑 변수, n(단순빈도))

사실 기리보이 9집 가사 한줄을 단위로 잡아서 tf-idf를 구하는 것은 의미가 없다.
제대로 하려면 9집 가사 중에서 노래별 가사를 단위로 잡았으면 더 의미있는 결과가 나왔을 것 같다.
다음에는 이렇게 시도해보기로 하고 오늘은 tf-idf를 구하는 방법을 익히는 것에 의의를 두기로 했다.
4. 워드 클라우드
저번 포스팅에서도 워드클라우드에 대해 다루었지만 오늘은 디자인적 요소들에 대해 더 자세히 다뤄보겠다.
1) 단순 출현 빈도 계산
song_result %>%
count(pos_clean, sort = T) -> cloud워드클라우드를 만들기 위한 가장 첫 단계는 단순 출현 빈도를 계산하는 것!!
tf-idf를 계산할 때와 달리, group_by 없이 구하기

cloud = cloud[-c(1,2,7,8,10,13,19),]# 보다,하다, 나다, 되다, 있다, 없다, 같다
cloud %>% head(200) -> cloud_result
여기서 글자 자체로 의미를 알아보기 힘든 동사들은 제거했다.
(아까 사랑했나 봐의 "봐"가 "보다"로 변해 의미 퇴색 등의 이유...)
2) 워드클라우드 그리기
# 색깔
devtools::install_github("jkaupp/nord")
library(nord)
pal = nord(palette = "afternoon_prarie", 200, reverse = T)
# 폰트
library(extrafont)
font_import()
loadfonts(device="win")
# 워드 클라우드
library(wordcloud2)
set.seed(22)
WC = wordcloud2(cloud_result,
fontFamily = "Daehan",
size = 0.5,
color = pal)아래 링크에는 R에서 사용할 수 있는 색깔 패키지에 대해 정리해 둔 글이다.
내가 잘못한건지 몇 개는 실행이 제대로 안되었다ㅠㅠ
github.com/EmilHvitfeldt/r-color-palettes
EmilHvitfeldt/r-color-palettes
Comprehensive list of color palettes available in r ❤️🧡💛💚💙💜 - EmilHvitfeldt/r-color-palettes
github.com
3) png로 저장
# html 형식으로 저장
library(htmlwidgets)
saveWidget(WC, "giriboy.html", selfcontained = F)
# html 형식을 png로 변환
webshot::install_phantomjs()
library(webshot)
webshot("giriboy.html", "giriboy.png",
delay = 5, # 스크린샷을 찍을 때 기다리는 시간,
# 워드클라우드 나올 때 걸리는 시간이 있어서 안해주면 내용 다 저장 안됨
vwidth = 1000, vheight = 1000)wordcloud2 같은 경우에는 plot창이 아닌 viewer창에서 그려지기 때문에 2번의 과정을 거쳐야 했다.
전 보다는 훨씬 깔끔하고 예쁜 워드클라우드가 완성되었다.


이거는 포토샵의 도움을 좀 받았다.
사실 figpath 기능과 lettercloud 기능을 사용하고 싶었으나 똥컴에서는 실행이 안된다ㅠㅠ(맥북을 사야할 또다를 이유가 생겼다ㅎ)
워드클라우드로 살펴 본 결과, 역시 기리보이하면 술과 찌질함 이별..ㅋㅋㅋ
취하다, 뻔하다, 아무것(아무것도 아니다에서 나온듯), 추억 등과 같이 이별전용 단어들이 눈에 띈다.
사실 "친구"라는 단어가 제일 많이 나왔는데(우리서로사랑하지는 말자의 힘..ㅎ) 기리보이 사진에 가려 잘 보이지 않는다.
이건 내가 디자인을 잘 못한 거다ㅠㅠ 잘 보이게 했어야 됐는데..(figpath만 됐어도..ㅠㅠㅠㅠㅠ)
반드시 컴을 바꿔서 figpath를 적용한 예쁘고 가독성이 더 뛰어난 워드클라우드를 만들어야지!!
번외_형태소 정보 제거하지 않고 단순 출현 빈도 분석!!
강사님께서 형태소 정보(/n,/p 등등)을 제거하지 않고도 단순 출현빈도를 계산해보라고 하셨는데,
직접 해보고나니 왜 그런 말씀을 하셨는지 더욱 이해가 갔다.
# 형태소 단위로 자르기
song %>%
mutate(sent_order = 1:n()) %>% # 문장 순서 만들기
unnest_tokens(pos, value, SimplePos09) -> song_pos
# 단순 출현 빈도
song_pos %>%
filter(!str_detect(pos, "^[A-Za-z].*/")) %>% # "/" 앞에 영어인 값 제거
filter(!str_detect(pos, "^./")) %>% # "/" 앞에 글자 하나인 경우 제거
count(pos, sort = T)
일단, 형태소 정보를 제거하지 않고서 영어단어를 걸러내기 위해서는 좀 더 복잡한 정규표현식이 필요했다.
형태소 정보를 전부 제거하고 난 후 영단어를 거를 때는 "[A-Za-z]" 라는 간단한 정규식으로도 가능했지만
지금은 형태소 정보가 영어이기 때문에 "[A-Za-z]" 이렇게 지우면 데이터가 아무것도 남지 않는다!
또 글자가 하나인 것은 의미가 없어서 걸러주는 과정에서는 형태소 정보가 남아있기 때문에 단순 글자 수가 > 1 로 표현하는 것이 아니라 "/" 앞의 글자가 한개라는 것을 정규식으로 표현해 주었다.

그 결과, 형태소 정보를 제거하고 count 했을 때보다 훨씬 더 의미있는 단어들이 위에 위치하고 있음을 확인했다.
아까는 "하다", "보다", "되다" 이런 단어들을 따로 제거해줘야 했지만 지금은 그럴 필요가 없이 유의미한 단어들이 상위에 count 되었다!!
song_pos %>%
filter(!str_detect(pos, "^[A-Za-z].*/")) %>% # "/" 앞에 영어인 값 제거
filter(!str_detect(pos, "^./")) %>% # "/" 앞에 글자 하나인 경우 제거
mutate(pos_clean = str_remove(pos,"/.*$")) %>% # 워드클라우드를 생성하기 위한 작업
count(pos_clean, sort = T) -> cloud_result2
# 워드 클라우드
library(RColorBrewer)
set.seed(22)
pal = brewer.pal(3, "Greys")
wordcloud2(cloud_result2,
fontFamily = "Daehan",
size = 0.5,
color = pal,
shape = "triangle"
)
유의미한 결과를 얻었으니 이를 워드클라우드로 표현해보자!!
다만 워드클라우드에도 형태소 정보를 붙인채 표현할 수 없으니 전부 제거해주었다.

그 결과, 데이터를 손수 거르지 않고도 아까와 비슷한 워드클라우드를 얻었다. ( 내용면에선 더 나은 것 같기도)
아무래도 노래 가사는 구어체이고 글 보다는 어미가 축약되고 다양하게 쓰이다 보니
형태소 정보를 유지한 채 분석한 것이 좀 더 유의미한 결과를 얻을 수 있었다.
다만, 단점은 단어의 끝맺음이 완벽하지 않은 채로 워드클라우드에 반영된다는 것이다.
형태소 정보를 제거하면 워드클라우드에서 깔끔한 단어를 볼 수 있는 대신,
의미가 없음에도 상위에 랭크되어 있는 용언들을 정성적으로 판단해서 지워야 한다는 단점이 있다.
두 방법 모두 장단점이 명확하니 강사님이 말씀하신대로 두 방법을 모두 실행해본 뒤
상황에 맞게 결정하는 것이 가장 바람직한 것 같다.
이렇게 T아카데이 "R로하는 텍스트 전처리" 복습은 마무리 되었다!!
기사 내용은 지루해서 내 나름 마음이 가는 소재들로 복습을 해보았다.
아직 부족한 점이 많지만 차차 보완해갈수있길..
가야할 길이 구만리지만 화이팅..!!
'Data' 카테고리의 다른 글
| [python] 네이버 뉴스 기사 작성일, 제목, url 크롤링 ( BeautifulSoup ) (378) | 2021.02.16 |
|---|---|
| [python] SVM, PCA kaggle 필사 (유방암 데이터) (691) | 2021.02.05 |
| [R] 데이터 시각화 with R ( 롤리팝차트 / 덤벨차트 / 슬로프차트 ) (387) | 2021.01.28 |
| [R] 데이터 시각화 with R ( 막대그래프/와플차트 ) (384) | 2021.01.26 |
| [R] R로 하는 텍스트 전처리( tidytext / KoNLP / wordcloud2 ) (378) | 2021.01.12 |


