오늘은 백만년만에 블로그 포스팅을 해보려한다..
무신사 상품 리뷰 크롤링은 이번년도 상반기에 비저블 활동을 하면서 마지막 조별 과제에서 하게되었다! (이게 벌써 반년이 다 되어가다니)
물론 결과적으로 주제가 바뀌어 크롤링 결과는 쓸모가 없게 되었지만..그래도 녹슬은 크롤링 감을 되돌리는데 좋은 기회가 되었다.
취직 이후 아예 이쪽 공부는 손을 놓아버리고 회사에 적응하느라 급급했었는데 (사실 아직도 적응 못함😅) 이번 포스팅을 시작으로 다시 새로운 맘으로 공부해보려고한다!!!
서론이 너무 길었네..바로 시작!!
일단 우리 조의 주제는 "무신사 스탠다드" 상품의 리뷰 분석이었다.
다들 알다시피 "무신사 스탠다드" 상품은 매우 많기에 상품의 리뷰를 긁어오기 위해서는 1) 각 상품의 제목과 url을 먼저 긁어온 후 2) 개별 url로 들어가 각 상품의 리뷰를 긁어와야 했다.
오늘 포스팅에서는 각 상품의 제목, 가격, url 긁어오기를 다루려고 한다.

오늘은 이전 포스팅과 다르게 아주 코드 짜는 과정을 하나하나 다루려한다. (왜냐하면 파이썬을 안 킨지 백만년이라 나도 내 코드를 다시 이해해야할 지경이기 때문이다^ㅡ^)
1. 모듈 불러오기
import selenium
from selenium import webdriver as wd
import time
import pandas as pd
from bs4 import BeautifulSoup
import requests
from itertools import repeat
import re사실 오늘 포스팅에서 selenium은 필요없지만 그냥 나는 크롤링을 할 경우 이 모듈을 복붙해서 사용한다. (그냥 귀찮기 때문)
오늘은 BeautifulSoup만으로도 충분하다.
2. html 정보 가져오기
url = 'https://www.musinsa.com/brands/musinsastandard?category3DepthCodes=&category2DepthCodes=&category1DepthCode=&colorCodes=&startPrice=&endPrice=&exclusiveYn=&includeSoldOut=&saleGoods=&timeSale=&includeKeywords=&sortCode=emt_high&tags=&page=1&size=90&listViewType=small&campaignCode=&groupSale=&outletGoods=false&boutiqueGoods='
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
# soup에 해당 url 페이지의 parsing된 html 정보 모두 담기게 됨
3. f12키를 눌러 내가 가져오려는 항목이 있는 html 파악하기
class = "img-block"에 내가 원하는 상품 url과 상품 title이 담겨있는 것을 확인했다.
(지금 보니까 class="list_info"를 사용하는 편이 더 좋아보이는데, 6개월 전 나 자신은 이걸 사용했으니 그대로 사용하겠다. 사실 아무렴 상관없다. 내가 원하는 정보만 잘 담겨있으면 된다.)
soup.find_all('a', attrs={'class':'img-block'})이렇게 해당 페이지의 모든 상품 url과 가격이 불러져온다.
4. 상품 url/ 상품 제목 가져오기
위 이미지를 보면 url은 href에, 상품제목은 title에 담긴걸 알 수 있다.
따라서 아래 코드로 첫번째(0번째) 상품의 url과 상품제목을 가져올 수 있다.
soup.find_all('a', attrs={'class':'img-block'})[0]['href'] # url
soup.find_all('a', attrs={'class':'img-block'})[0]['title'] # 상품제목
5. 상품 가격 가져오기
상품의 가격은 p class="price"에 담겨있다.
또 아까 제목이나 url처럼 속성에 담겨있는게 아니라, 값으로 담겨 있기에 이럴때는 get_text() 함수를 이용해주면 된다.
soup.find_all('p', attrs={'class':'price'})[0].get_text()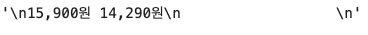
크롤링할 당시에는 원래 가격만 담겨있었는데, 갑자기 세일하는 바람에 가격을 2개를 들고오네^^
따라서 1) 원래 가격만 가져오면서 2) 쓸데없는 \n과 같은 기호는 제외하고 숫자만 가져와야 한다.
soup.find_all('p', attrs={'class':'price'})[0].get_text().split()[0]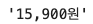
15,900원과 14,290원은 띄어쓰기로 나눠져있으므로 split 함수를 통해 나눈 후 첫번째 인덱스만 가져오면 된다.
최종적으로 정규표현식을 사용해서 숫자만 남기면 끝!!
[re.sub(r'[^0-9]', '', soup.get_text().split()[0]) for soup in soup.find_all('p', attrs={'class':'price'})]
6. 전 페이지 상품 모두 가져오기
이제 페이지를 넘기면서 모든 페이지에 있는 상품을 가져와야한다.
이를 위해 페이지 규칙성을 파악해야하는데 무신사의 경우 매우 간단하다. (만약 페이지별로 url이 다르다면 selenium을 사용해야한다!)
start = 1
title_list = []
url_list = []
# price_list = []
while start<37: #1페이지~36페이지
try:
url = 'https://www.musinsa.com/brands/musinsastandard?category3DepthCodes=&category2DepthCodes=&category1DepthCode=&colorCodes=&startPrice=&endPrice=&exclusiveYn=&includeSoldOut=&saleGoods=&timeSale=&includeKeywords=&sortCode=emt_high&tags=&page={}&size=90&listViewType=small&campaignCode=&groupSale=&outletGoods=false&boutiqueGoods='.format(start)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
for soup in soup.find_all('a', attrs={'class':'img-block'}):
title_list.append(soup['title'])
url_list.append('https:' + soup['href'])
start += 1
except:
print(start)
break크롤링할 당시 무신사 스탠다드 페이지가 36페이지까지여서 그대로 사용했다.
또 가격은 필요없게 되어서 당시 수집하지 않았었고
url의 경우 바로 접속 가능하도록 애초에 크롤링할때 'https:'를 붙여서 가져왔다.
df = pd.DataFrame({'상품명': title_list,
'url': url_list})
df.to_csv('무신사.csv', encoding = 'utf-8-sig')마지막은 언제나 그랬듯이 데이터 프레임으로 변경한 후, 인코딩해서 csv로 저장~
다음번엔 이렇게 수집한 url로 접속해서 상품리뷰를 크롤링하는 과정을 포스팅할거다!!
'Data' 카테고리의 다른 글
| [업무자동화][python] 회사 엑셀 파일 가공하기 (feat. groupby, pivot_table) (0) | 2024.10.07 |
|---|---|
| [업무자동화][python] 회사 엑셀 파일 가공하기 (feat. xlwings) (0) | 2024.08.11 |
| 게임 사용자 관리 비즈니스 시나리오 (420) | 2022.03.26 |
| [Tableau] 쿠폰 성과 측정 대시보드 (753) | 2022.02.27 |
| [Tableau] 반품 고객 관리 대시보드 (비저블 합격!) (386) | 2022.01.10 |



