백만년만의 포스팅...
이제 더이상 쓸 일이 없을 것이라고 생각했던 파이썬을 회사에서 데이터 가공업무에 사용하게 되었는데..
자주 쓰지 않으니 또 사용할 일이 생기면 기억하고자 아주 오랜만에 포스팅하게되었다!
우선 데이터 가공업무에 엑셀 파워쿼리, 파워BI가 아닌 잘 하지도 못하는 파이썬을 굳이 사용하게 된 이유는 바로 엑셀 문서 보안 DRM 때문이다.
파이썬의 xlwings 모듈로 DRM 문서를 불러오는 것이 가능했고 이게 내가 찾아낸 유일한 해결방법이었기에..
앞으로 프로젝트를 하면서 고객사는 분명 방대한 양의 데이터를 엑셀로 제공할 것이고...
엑셀로 취합하다 틈만나면 죽어버리는 엑셀에 답답해서 죽지 않기 위해 가공 방법을 기록하고자 한다.
# 1. 데이터 구성 및 설명

보통의 회사가 데이터를 제공해주는 방식.
시스템 내 데이터를 연도별로 폴더에 나누어 캡쳐와 같이 전달해준다.
물론 가상 데이터임!
데이터 구조는 아래와 같다.
1) 01 물자 ~ 03 공사는 아래와 같은 동일한 구조로 생성
| 송장년도 | Plant | Plant내역 | 자재코드 | 지출결의금액 | 통화 |
| 2020 | 0001a | a | 100112 | 100089 | USD |
| 2020 | 0001b | b | 100112 | 39445080 | KRW |
| 2020 | 0001c | c | 100112 | 890045 | KRW |
| 2020 | 0001d | d | 100112 | 77309871 | KRW |
2) VMI 만 아래와 같이 다른 구조로 생겼다.
데이터 컬럼구조도 다르고, 동일한 데이터라더라도 컬럼명이 조금씩 다르다.
| 회계년도 | Plnt | 플랜트명 | 자재번호 | 지출결의금액 | 통화 | VMI코드 |
| 2020 | 0001a | a | 100112 | 100089 | USD | 1023 |
| 2020 | 0001b | b | 100112 | 39445080 | KRW | 3044 |
| 2020 | 0001c | c | 100112 | 890045 | KRW | 234 |
| 2020 | 0001d | d | 100112 | 77309871 | KRW | 323 |
3) 그래서 결국 만들고자 하는 최종 데이터 테이블 형태!
| 송장년도 | Plant | Plant내역 | 자재코드 | 지출결의금액 | 통화 | 품목군 | L2 | L3 |
| 2020 | 0001a | a | 100112 | 100089 | USD | 물자 | ||
| 2020 | 0001b | b | 100112 | 39445080 | KRW | 물자 | ||
| 2020 | 0001c | c | 100112 | 890045 | KRW | 수주 | 비투자 | 공사 |
| 2019 | 0001d | d | 100112 | 77309871 | KRW | 수주 | 투자 | 자재 |
| 2019 | ... | ... | ... | ... | ... | ... | ... |
이러한 최종테이블을 생성하기 위한 조건은 아래와 같다.
즉, 모든 데이터를 합치되, 구분자 컬럼을 포함하는 것
조건 1. 2019~2020 년도에 있는 모든 데이터를 합친다. (주의사항. VMI는 컬럼구조가 다르므로 나머지 테이블과의 구조를 일치시켜줘야한다.)
조건 2. 02_수주의 경우 투자/비투자로 나뉜다. 이를 L2 컬럼에 포함한다.
조건 3. 02_수주의 경우 자재코드 데이터가 존재하면 L3에 자재, 존재하지 않으면 L3에 공사로 명시한다.
#2. 데이터 읽어오기
2-1. 읽어야하는 파일 경로를 모두 모은다 -> 리스트로 생성
2-2. 반목문을 통해 데이터를 모두 읽는다
단, 여기서 VMI의 경우 나머지 파일과 구조 일치 시켜야함
2-1. 읽어야하는 파일 path 모두 모아 리스트 만들기
import pandas as pd
import xlwings as xw
import os
# 폴더 경로
path_2019 = './2019_지출결의금액' # 2019 데이터 폴더경로
path_2020 = './2020_지출결의금액' # 2020 데이터 폴더경로
# 폴더 내 파일명 리스트로 가져오기
file_list_2019 = os.listdir(path_2019) #os.listdir 경로 내 파일을 리스트로 모두 가져옴
file_list_2020 = os.listdir(path_2020)
# 각 파일 경로 만들기 (폴더경로 + 파일명)
file_path_list = [path_2019 + '/' + i for i in file_list_2019 if i.endswith('.xlsx')] + [path_2020 + '/' + i for i in file_list_2020 if i.endswith('.xlsx')]
여기서 혹여나 엑셀 파일이 아닌 다른 형식의 파일이 포함되어있을 수 있으므로
endswith('xlsx.') 조건문을 넣어줬다.
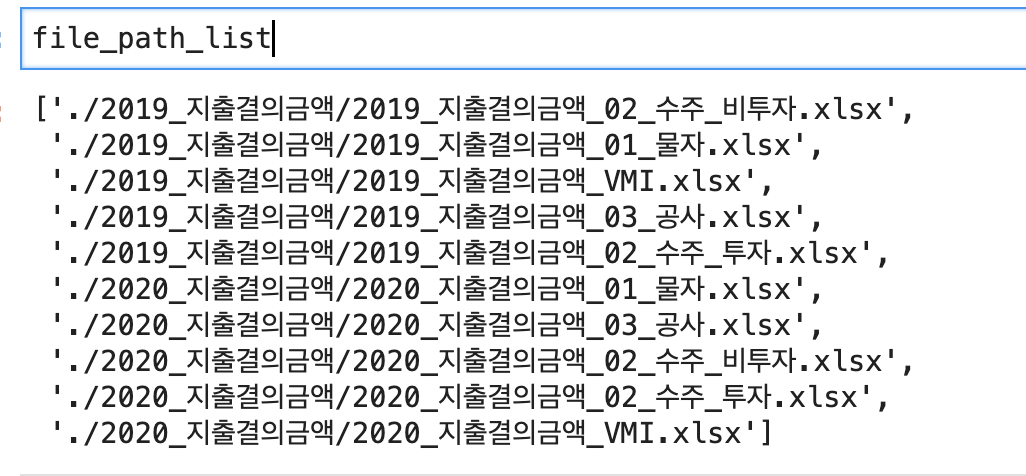
그래서 나온 최종 결과물 file_path_list !
사실 파일 개수가 적다면 그냥 수작업으로 리스트 만드는 게 훨씬 빠르지만,
파일이 굉장히 많을 경우를 대비하여 파일명을 자동으로 불러오는 (listdir)을 사용해보았다.
2-2. 반목문을 통해 데이터를 모두 읽기 (단, 여기서 VMI의 경우 나머지 파일과 구조 일치 시켜야함)
df_result = pd.DataFrame() # 빈 데이터프레임 생성
for file_path in file_path_list:
book = xw.Book(file_path) # 엑셀파일경로
sheet = book.sheets[-1] # 파일 내 읽어올 sheet 지정
df = sheet.used_range.options(pd.DataFrame, index=False).value #엑셀 데이터를 데이터프레임으로 불러옴
#데이터 가공
# VMI 데이터 가공
# 나머지 데이터와 일치하는 컬럼만 가져오기 + 컬럼명 나머지 데이터와 일치시키기
if 'VMI' in file_path :
df = df[['회계년도','Plnt','플랜트명','자재번호','지출결의금액','통화']].rename(
columns = {'회계년도':'송장년도','Plnt':'Plant', '플랜트명':'Plant내역','자재번호':'자재코드'} )
# 파일경로를 구분자 컬럼으로 넣어주기
df['file_path'] = file_path
# 데이터 합치기
df_result = pd.concat([df_result, df] , ignore_index = True, axis = 0 ) # 데이터 행 합치기
결과로 나온 df_result
2019~2020 데이터 총 40행이 정상적으로 잘 나왔다.
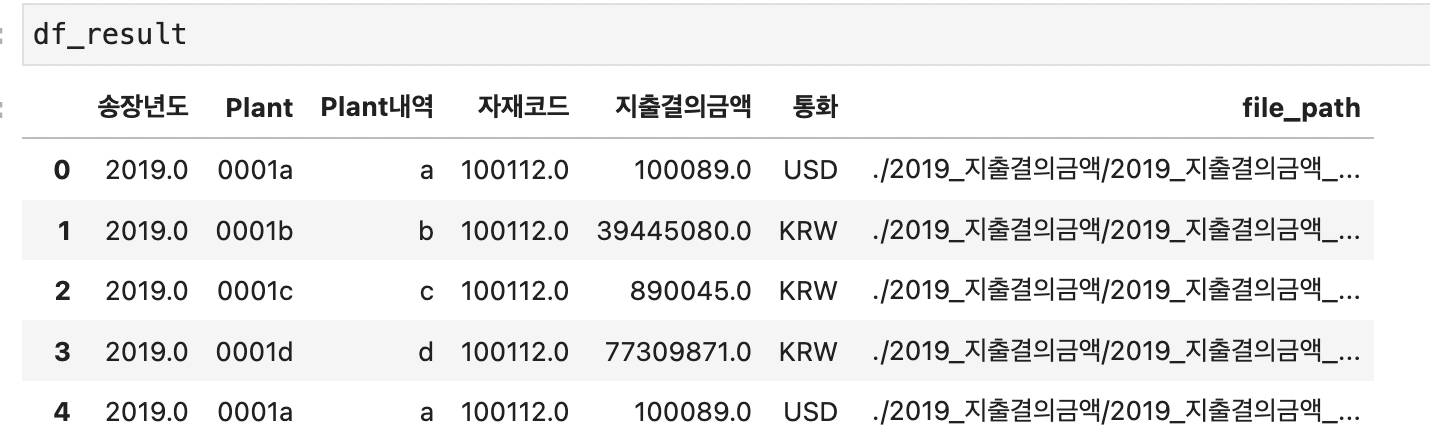
xlwings를 사용하면 마치 크롤링하듯이 엑셀 파일이 전부 열리면서 파이썬이 데이터를 읽어온다.
pd.concat을 사용하려면 데이터 컬럼명이 모두 같아야하기 때문에 VMI 데이터도 rename 함수를 통해 컬럼명을 일치시켜줬다.
# 3. 데이터에 구분자 컬럼 추가하기
최종적으로 아래 표와 같은 데이터 형태가 되기 위해, 세 컬럼을 추가해야한다.
3-1. "품목군"컬럼 생성하기 (파일경로 사용)
3-2. "품목군" 이 "투자 or 비투자"인 경우 -> "품목군" 수주로 변경, 투자/비투자는 컬럼 "L2"로
3-3. "품목군"이 수주이면서, 자재코드 유무에 따라 L3 자재/공사로 명시
| 송장년도 | Plant | Plant내역 | 자재코드 | 지출결의금액 | 통화 | 품목군 | L2 |
| 2020 | 0001a | a | 100112 | 100089 | USD | 물자 | |
| 2020 | 0001b | b | 100112 | 39445080 | KRW | 물자 | |
| 2020 | 0001c | c | 100112 | 890045 | KRW | 수주 | 비투자 |
| 2019 | 0001d | d | 100112 | 77309871 | KRW | 수주 | 투자 |
| 2019 | ... | ... | ... | ... | ... | ... | ... |
3-1. "품목군"컬럼 생성하기 (파일경로 사용)
df_result['품목군'] = df_result['file_path'].apply(lambda x : x.strip('.xlsx').rsplit('_')[-1])
반복문으로도 가능하지만,
1. 데이터 프레임에서
2. 특정 컬럼의 데이터를 기반으로
3. 새로운 컬럼을 추가하는 경우
apply(lambda) 조합을 사용하면 굉장히 편하다.
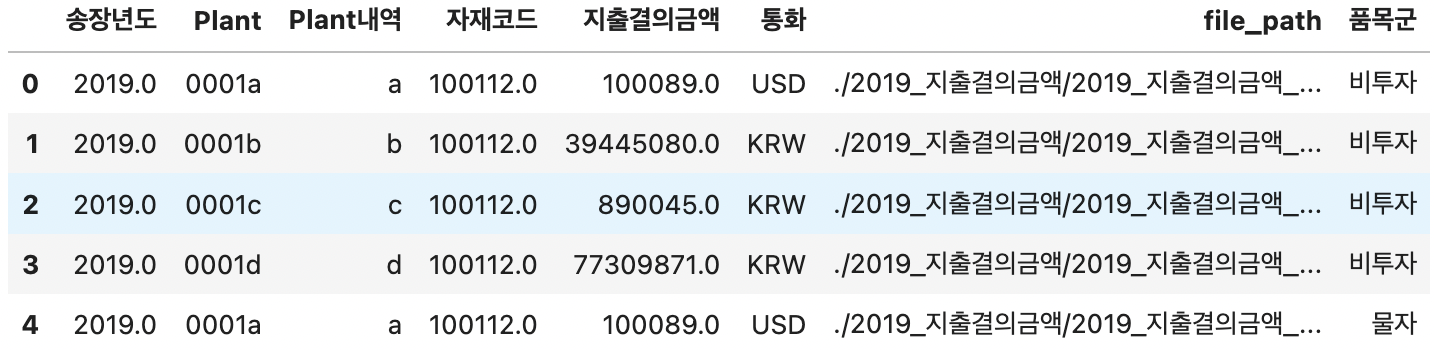
3-2. "품목군" 이 "투자 or 비투자"인 경우 -> "품목군" 수주로 변경, 투자/비투자는 컬럼 "L2"로
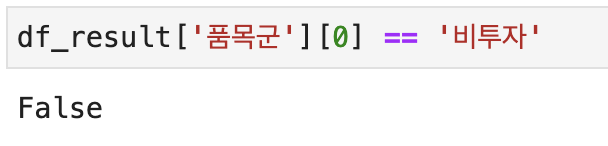
이 단계에서부터 문제가 생겼는데...
"품목군" 내 데이터를 명확히 인식하지 못하는것.. 분명 같은 한글인데...
https://jonsyou.tistory.com/26
[Python] 한글 내용이 같지만 다르다고 인식하는 경우
분석 환경 Google Colab pro의 구성환경 Python Version : 3.7.10 상황 눈으로 볼 땐 두 한글 변수의 값이 같지만 비교 연산자 실행 시 다르다고 인식하는 상황. 더 나아가 두 변수를 같게끔 인식 시키고 싶
jonsyou.tistory.com
import unicodedata
df_result['품목군'] = df_result['품목군'].apply(lambda x : unicodedata.normalize('NFC',x)) #NFC는 분리된 자음/모음을 합침
결과적으로 위 링크를 통해 해결!
자음과 모음이 분리되어있던 것이 문제였다.
unicodedata 모듈을 설치하고 자/모음을 합쳐 글자 수를 맞추어주었다.
이제 다시 본론으로 들어와서..L2 만들기!
df_result['L2'] = df_result['품목군'].apply(lambda x : x if '투자' in x else "" )
df_result['품목군'] = df_result['품목군'].apply(lambda x : '수주' if '투자' in x else x )
3-3. "품목군"이 수주이면서, 자재코드 유무에 따라 L3 자재/공사로 명시
굉장히 간단한 반복문으로 해결하면 되지만,
여기서도 생각지도 못한 에러를 만났는데..

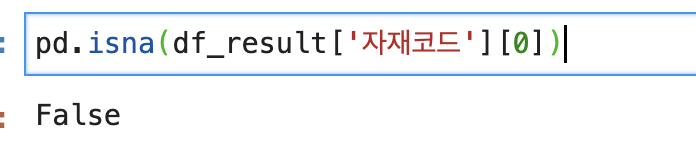
isna 는 "데이터프레임"에서 결측값을 찾기 위한 함수로..데이터프레임 혹은 데이터프레임의 행/컬럼에만 적용된다..
특정값에 적용하려면...pd.isna를 사용하면됩니다..
(이것때문에 결측값 다 다른값으로 대체해야하나 고민한 바보 여기 있음)
for i in range(len(df_result)):
if df_result.loc[i, '품목군'] == '수주':
if pd.isna(df_result.loc[i,'자재코드']) :
df_result.loc[i, 'L3'] = '공사'
else:
df_result.loc[i, 'L3'] = '자재'
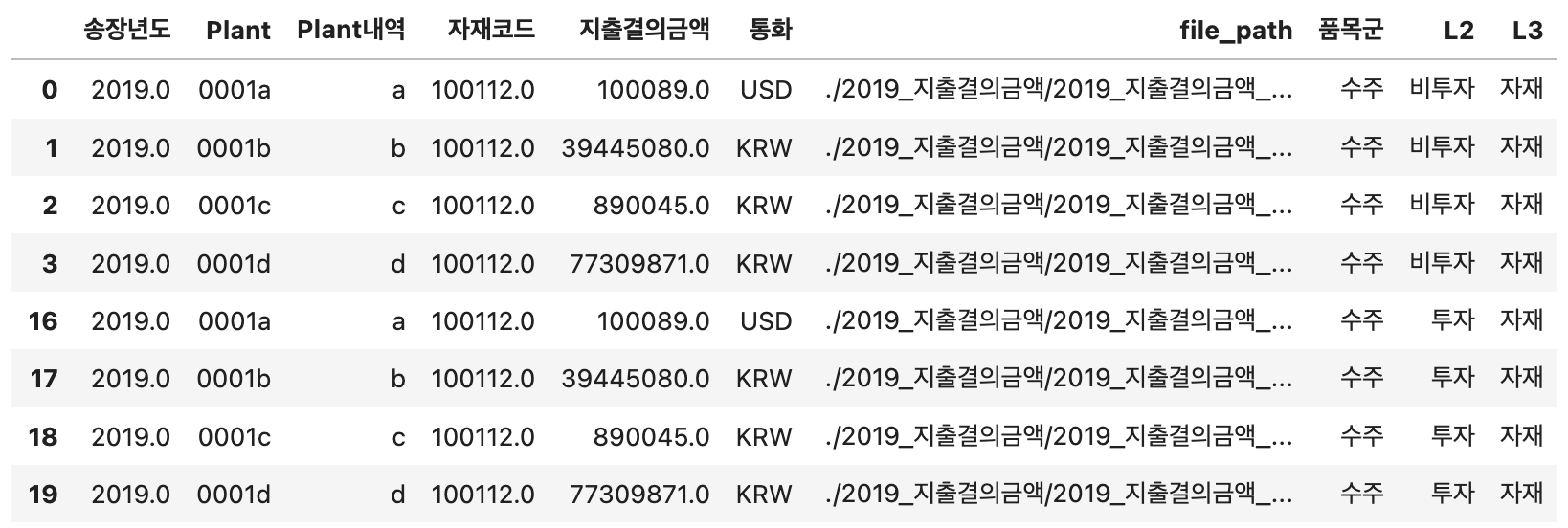
# 품목군이 수주인 데이터만 추출하여 확인
df_result[df_result['품목군'] == '수주']
원하는 형식으로 데이터 생성 완료!!
생각보다 포스팅이 길어져서..
생성된 데이터기반으로 pivot 테이블 만드는 내용은 다음 포스팅으로~
'Data' 카테고리의 다른 글
| [업무자동화][python] 회사 엑셀 파일 가공하기 (feat. groupby, pivot_table) (0) | 2024.10.07 |
|---|---|
| [python] 무신사 상품 리뷰 크롤링1. 상품 url/제목/가격 가져오기 (BeautifulSoup, 정규표현식) (383) | 2022.11.06 |
| 게임 사용자 관리 비즈니스 시나리오 (420) | 2022.03.26 |
| [Tableau] 쿠폰 성과 측정 대시보드 (753) | 2022.02.27 |
| [Tableau] 반품 고객 관리 대시보드 (비저블 합격!) (386) | 2022.01.10 |



